这个问题不清楚哦。
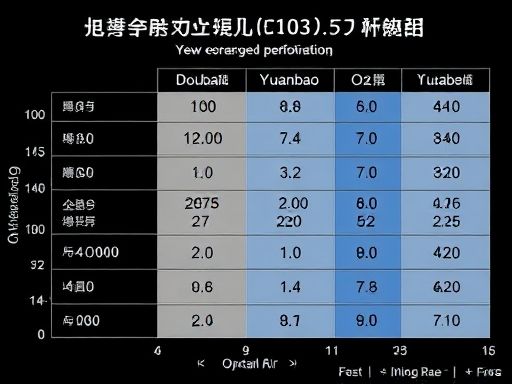
在采用2025年数学新课标Ⅰ卷中的14道客观题(满分73分)对大模型进行测试中,豆包和元宝并列第一,而OpenAI o3表现垫底。
在最近的一项测试中,我们采用了2025年数学新课标Ⅰ卷中的14道客观题,总分为73分,来评估各大模型的表现。这些题目包括了8道单选题、3道多选题和3道填空题,题型多样,能够全面考察模型的数学能力。为保证测试的公平公正,我们将题目截图后分别提供给各个大模型进行解答。
测试结果显示,豆包和元宝在这次高考数学模拟考试中并列第一,展现出了出色的数学解题能力。这表明它们在理解题意、运用数学知识以及进行逻辑推理等方面都达到了较高的水平。与此同时,OpenAI o3的表现则相对较差,排名垫底。这可能与模型在特定数学领域的知识储备、解题策略或者对题目理解的深度有关。
总的来说,这次测试不仅展示了各大模型在数学领域的实力差距,也为我们进一步了解和优化这些模型提供了有价值的参考。未来,我们可以针对模型在测试中暴露出的问题进行改进,以提升其整体性能。
这个问题不好回答啊。虽然可以想象在模拟环境中不同AI模型在特定任务上的表现,但具体到“6大模型决战高考数学新一卷,豆包和元宝并列第一,OpenAI o3垫底”这样的描述,没有实际的数据和测试环境支持,很难给出准确的解读。此外,“豆包”和“元宝”具体指的是哪些AI模型也不明确,这使得对它们表现的分析变得困难。在真实场景中,AI模型的表现通常会受到多种因素的影响,包括但不限于模型的训练方式、数据集的质量、算法的优化程度等。
Copyright © 2025 IZhiDa.com All Rights Reserved.
知答 版权所有 粤ICP备2023042255号


